Automatisation du Résumé du Journal Officiel par Modèles de Langage Légers
Approches : Prompt Engineering et Fine-Tuning
Joris Salmon
Nolwenn Chapellon
Année : 2024-2025 • Promotion Mars 2025
Contexte & Problématique

- Journal Officiel : volume immense, langage juridique complexe
- Défi d'accès à l'information pour les journalistes
- LLM : puissants, mais coûteux et peu adaptables
- SLM : économiques, agiles, et spécialisables
Comment générer des résumés rigoureux, synthétiques et exploitables du Journal Officiel, avec des modèles de langage légers ?
État de l'Art : Prompt Engineering
- Optimisation des instructions pour guider le LLM
- Objectif : réponses pertinentes sans modification du modèle
- Techniques : Zero-Shot et Few-Shot
- Approches avancées : Chain of Thought (CoT)
- Limite pour les SLM : Insuffisant sans adaptation profonde
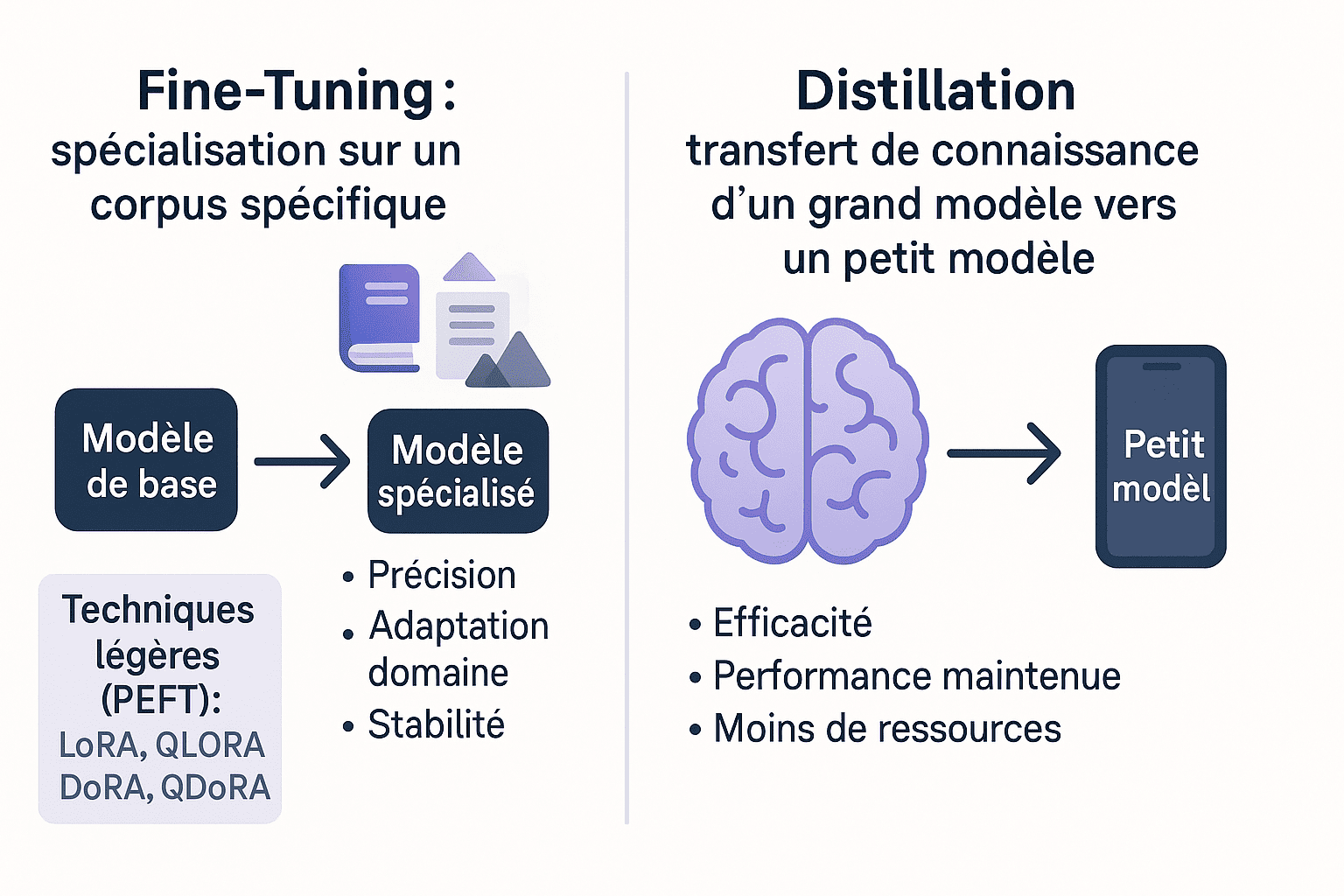
État de l'Art : Fine-Tuning & Distillation
- Fine-Tuning : spécialisation sur un corpus spécifique
- Apporte précision, stabilité, adaptation au domaine
- Techniques légères (PEFT) : LoRA, QLoRA, DoRA, QDoRA
- Distillation : transfert grand modèle → petit modèle
- Combinaison performance et efficacité
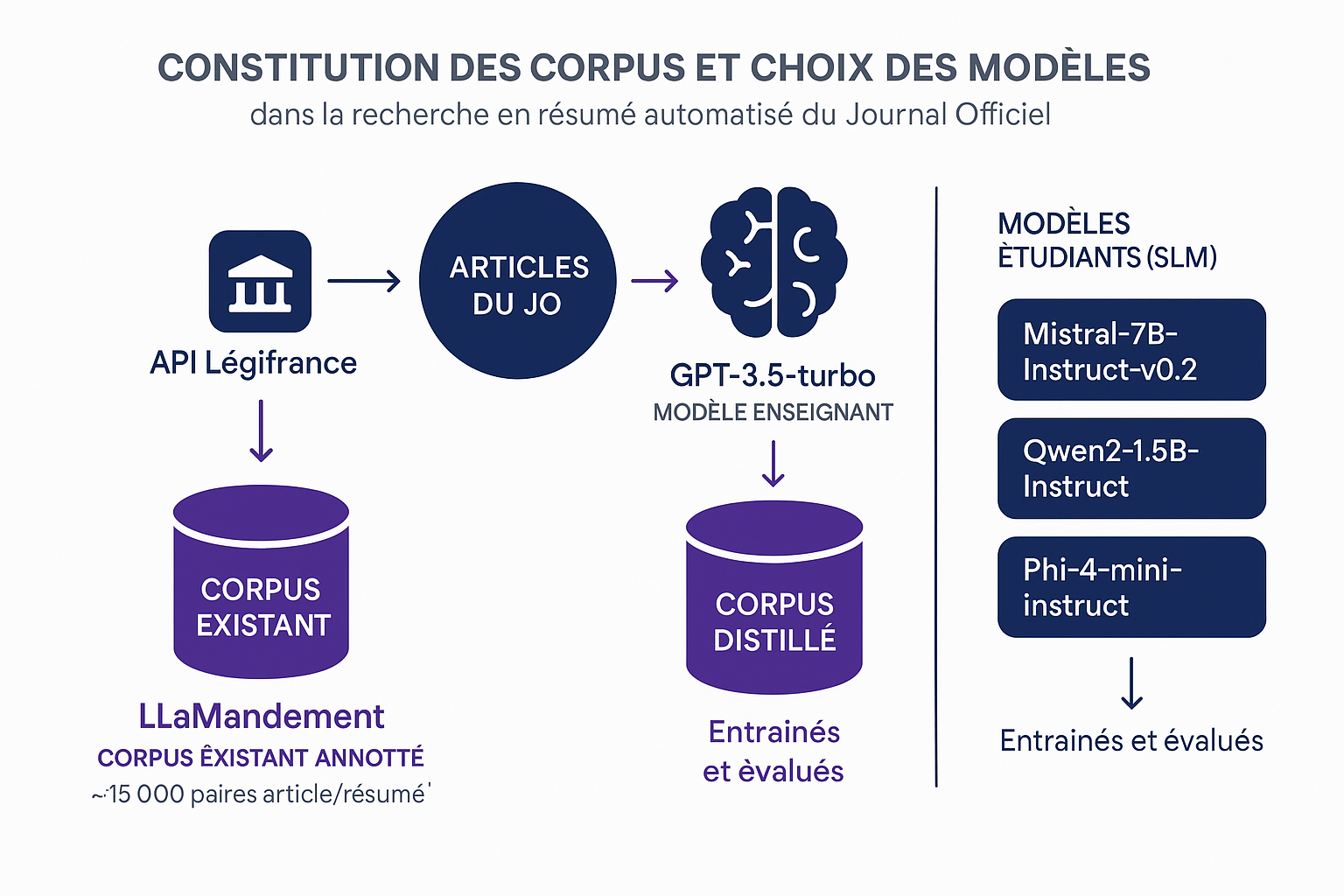
Méthodologie : Corpus & Modèles
Corpus : articles du Journal Officiel (API Légifrance)
- LLaMandement (~15 000 paires article/résumé)
- Corpus distillé : résumés générés par GPT-3.5-turbo
Modèles étudiants (SLM) :
- Mistral-7B-Instruct-v0.2
- Qwen2-1.5B-Instruct
- Phi-4-mini-instruct
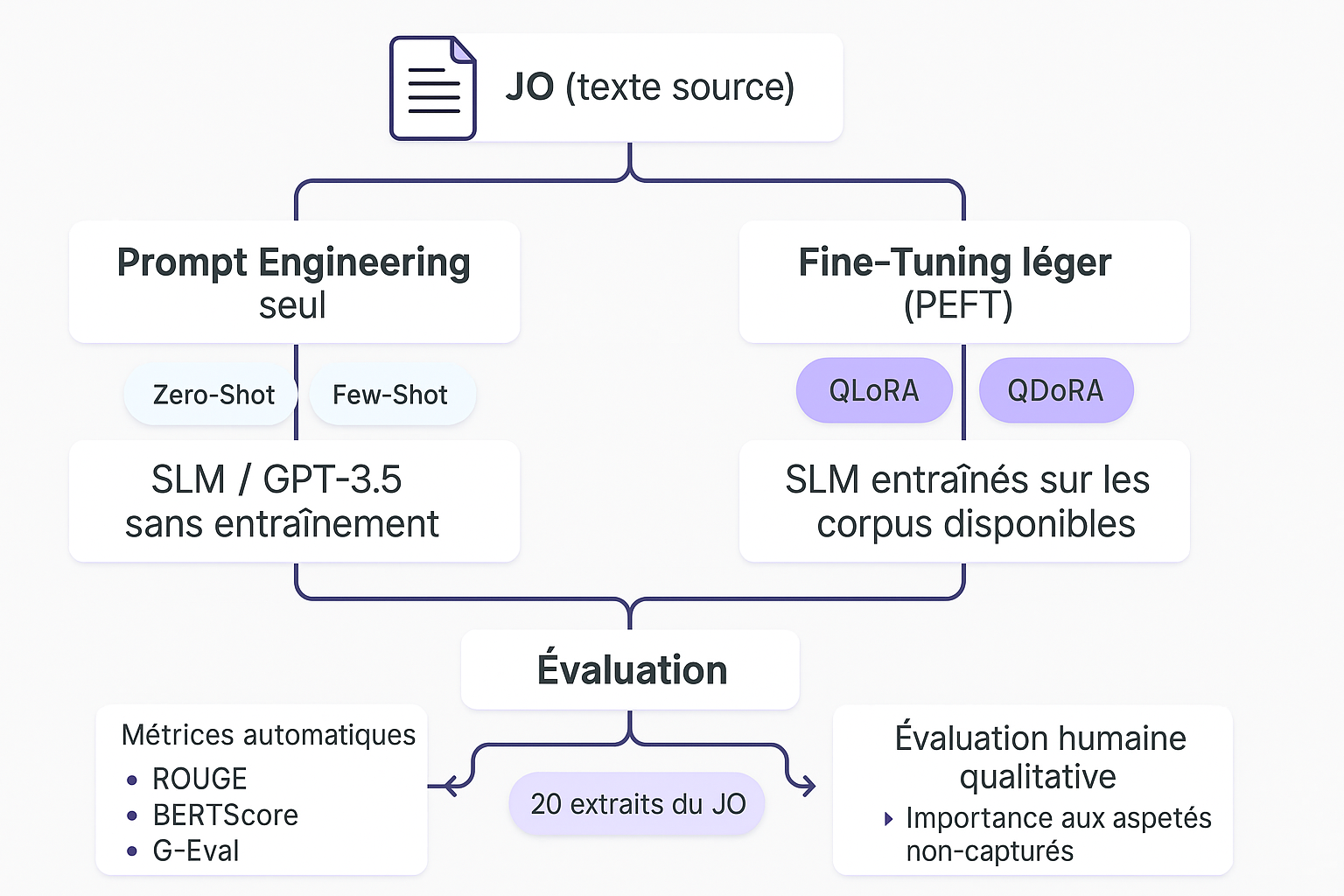
Méthodologie : Protocoles d'Expérimentation
Comparaison de deux approches :
- Prompt Engineering seul (Zero-Shot, Few-Shot)
- Fine-Tuning léger (PEFT) avec QLoRA et QDoRA
Évaluation sur 20 extraits du JO :
- Métriques automatiques : ROUGE, BERTScore, G-Eval
- Évaluation humaine qualitative
Hyperparamètres FT : Batch 1, Acc. 64, LR 1e-4, 4-bit quant.
Limites de l'Étude
- Ressources GPU limitées (contraintes sur modèles et itérations)
- Références générées par l'IA (GPT-4) : peuvent introduire des biais
- Volume de données d'entraînement modeste (limite la généralisation)
- Métriques automatiques : ne capturent pas toutes les nuances
- Nécessité de l'évaluation humaine complémentaire
- Test limité à un domaine législatif spécifique
- Variabilité des performances selon les types d'articles
Questions ?
Merci de votre attention !

Joris Salmon
Étudiant Master 2 Data Analytics
Nolwenn Chapellon
Étudiante Master 2 Data Analytics